- 새로운 뉴스를 올려주세요.
| Date | 23/01/26 22:45:41 |
| Name | 구밀복검 |
| Subject | "지하철 이용자는 전장연 시위 지지하기 어렵다" 사실일까? |
|
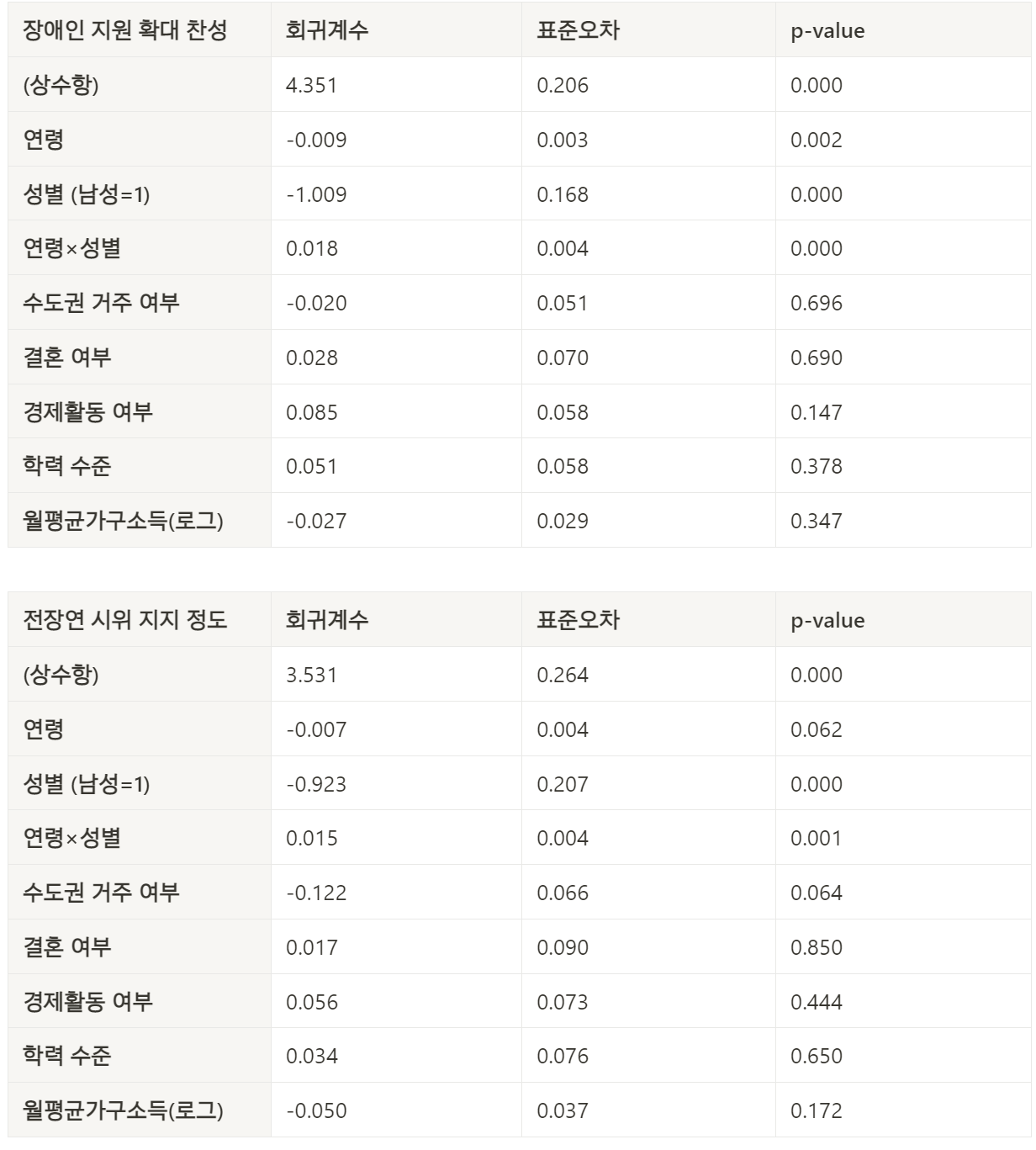
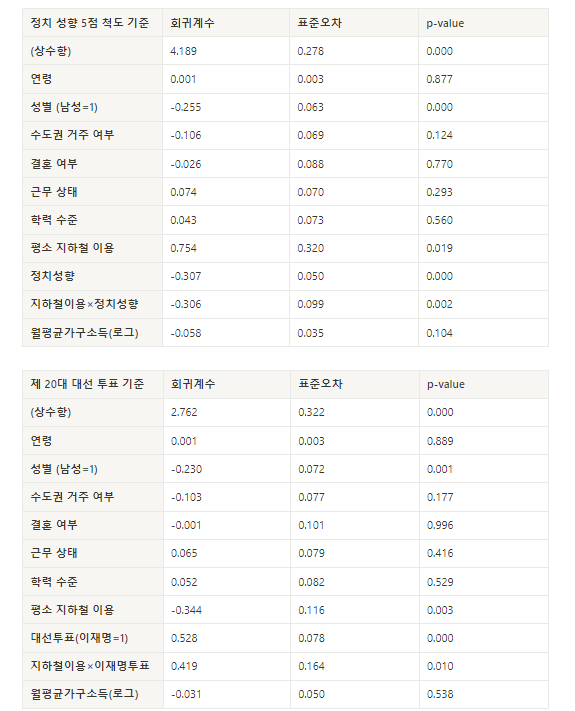
https://premium.sbs.co.kr/article/MnZdmi2TPf?fbclid=IwAR0x_yzIs0FwlJ97mOXB8owPzLIwVBX086Nlvkgv44qgAMNygUZThA-K8eY ..이번 시위와 관련해 온라인에서 접하는 대표적인 의견 중 하나는 “평소에 지하철을 이용하지 않는 사람들만 지지하지, 지하철 타고 다니는 수도권 사람들이라면 솔직히 이번 시위 지지하기 어렵다”입니다... 우선 주요 교통수단이 지하철이라고 답한 사람들은 여타 유형의 응답자들에 대비해 전장연 시위 지지도가 5점 만점에 0.21점 더 낮게 나타났습니다. 지하철 이용 여부는 시위 지지도와 유의미한 상관관계를 보였습니다.(p<.01) 여기까지만 보면 꽤 직관적인 결과이고, 우리의 통념이 사실인 것도 같습니다. 다만 여기서 한 가지 주의해야 할 부분이 있습니다. 과연 ‘실제 불편함’을 겪고 있는 수도권의 지하철 이용객들이 부정적인 응답을 한 것일까요, 아니면 전장연 시위를 직접 경험하지 않는 비수도권의 지하철 이용객들 역시 ‘심리적인 공감’을 이유로 부정적인 입장을 보인 것일까요? ... 분석 결과, [서울시민들에게는 평소 지하철 이용 여부가 시위 여론에 전혀 영향을 주지 못했고(p-value 0.452), 경기도민들과 비수도권 응답자들에게만 약한 수준의 영향이 나타났습니다.(p<.1)] 경기도민은 서울까지 긴 통근·통학 시간을 겪는 경우가 많기에 그 피해가 응답에 반영되었다고 볼 수 있겠지만, 직접 시위에 영향을 받는 서울시민에게는 정작 그러한 경향이 전혀 없었다는 점, 또 반대로 시위 영향권에 전혀 포함되지 않는 비수도권 시민들에게 오히려 약하게나마 상관관계가 관찰된 점을 고려하면, 분명 직접적인 불편함 이외의 심리적인 무언가가 전장연 시위 여론에 영향을 주었을 것도 같습니다. 즉, 우리의 통념은 절반만 사실이었던 것이죠. ...흥미로운 심리적 요소는 바로 ‘정치적 신념’입니다....각 후보 지지자마다 지하철 이용 여부에 따라 서로 다른 패턴이 나타난다는 것을 알 수 있습니다. 이재명 후보에 투표한 응답자들은 평소 지하철 이용 여부와 전장연 시위에 대한 의견이 무관했지만, 윤석열 후보에 투표한 응답자들은 평소 지하철을 이용할수록 시위에 대한 비판 여론이 더 심했습니다. (p<.0 5)... ...스스로가 매우 진보적이라고 응답한 사람들은 지하철을 이용할수록 시위에 우호적이었지만, 그래프의 오른쪽 막대들로 이동할수록, 즉 정치 성향이 보수적일수록 지하철 이용 경험이 시위 여론에 부정적인 영향을 주었죠. [즉, 사람들은 이미 지니고 있는 각자의 정치 성향에 따라 이미 장애인 이동권이나 시위에 관한 의견을 사전에 정립해 둔 후, 지하철을 대상으로 하는 전장연 시위를 사후에 접하게 되면서 기존 신념을 각자의 방식으로 강화했을 가능성이 있습니다.] 연령, 성별, 소득, 학력, 직업, 결혼 여부 중 전장연 시위 지지와 통계적으로 유의미한 관계가 있는 요소는 무엇일까요? 놀랍게도 연령과 성별 간의 교차효과(interaction effect)를 제외하면, 그 어떤 요인들도 전장연에 관한 의견에 영향을 주지 못했습니다. 고등학교까지만 교육을 받았든, 서울 4년제 대학교를 졸업했든, 월평균 소득이 높든 낮든, 결혼을 했든 안 했든 전장연의 시위에 우호적인지, 아니면 비판적인지와는 전혀 관련이 없었죠.... ...연령과 성별 간의 교차 효과가 의미하는 바는...[고연령층에서는 성별에 따른 의견 차이가 없었으나, 연령대가 낮아질수록 남녀 간의 여론에 급격한 차이]가 나타났죠. 20대와 30대의 청년들의 경우, 남성들 중 51.7%가 이번 시위를 정당한 권리 행사가 아닌 사회적 민폐라고 평가했지만 여성들은 그보다 훨씬 적은 38.1%가 그렇다고 답했습니다.... 전장연 시위가 아니라 더 광범위한 [장애인 지원 정책과 예산을 소재로 질문했을 때에도 동일한 양상]이 나타났습니다. 참고로 지난해 6월에 서울신문·공공의창·우리리서치가 진행한 유사한 설문조사에서도 이와 비슷한 결과가 나타난 바 있습니다. 재미있는 연구가 나왔네요 ㅎㅎ https://minvv23.notion.site/SBS-9fa03cede9d34da4beeda0501a46bd0b [단순히 지하철을 평소에 이용하는지 보다도 어떠한 정치 성향을 지닌 사람이 지하철을 이용하는지가 훨씬 더 전장연 여론에 중요한 요소였음] 13
이 게시판에 등록된 구밀복검님의 최근 게시물
|
|